
Multimodal Document Classification
Published:
The automatic classification of documents remains an important and only partially solved information management problem within the upstream oil and gas industry. Companies in this sector have typically amassed vast repositories of unstructured data measuring in the range of tens to thousands of terabytes. An estimated 80% of all data within the upstream oil and gas industry is stored within large unstructured document repositories.
Retrieving relevant documents from these large unstructured data repositories is a major challenge for the industry, with some reports suggesting that geoscientists and engineers spend over 50% of their time searching for data. Locating specific data such as porosity and permeability logs, well trajectories and composite wireline logs can be challenging.
Many of the document types found in such repositories are vital to informing exploration and risk management decisions, as well as to ensuring regulatory compliance. If crucial data is omitted from exploration models due to difficulties in its retrieval, this can lead to costly dry exploration wells or jeopardise the safety of a company’s operations.
Document Classification
Automated document classification algorithms aid information retrieval from these repositories by automatically identifying document types. These classifiers act in a similar manner to static search queries, which when combined with key word search, allow results to be refined to only include the data types a user is seeking to retrieve. The predicted classifications when used more broadly can also assist in providing data management oversight of the data within these repositories.
Recently, supervised machine learning has been widely used to create these algorithmic classifiers. With the machine learning algorithm learning a document classification prediction function from a pre-labelled corpus of representative documents. Historically these classifiers can learn document classifications at a granular level based on a documents text content or at a higher level based on image representations of their pages.
Multi-Modal Approach
The majority of documents in the upstream oil and gas domain are multimodal, meaning they rely on multiple channels to communicate information to the reader, relying on both textual and visual modalities for communication. For example most documents contain free text, often alongside text stored in tables, captions and figures. This text gives documents their semantic meaning and in many cases conveys the majority of the information.
However visual features such as a documents layout, colour distribution, text formatting, charts and image content provide supplementary meaning alongside text based features. In some cases visual features will convey the majority of the information, examples of exploration documents that primarily communicate information visually include sample images, maps, technical diagrams, seismic sections and wireline logs.
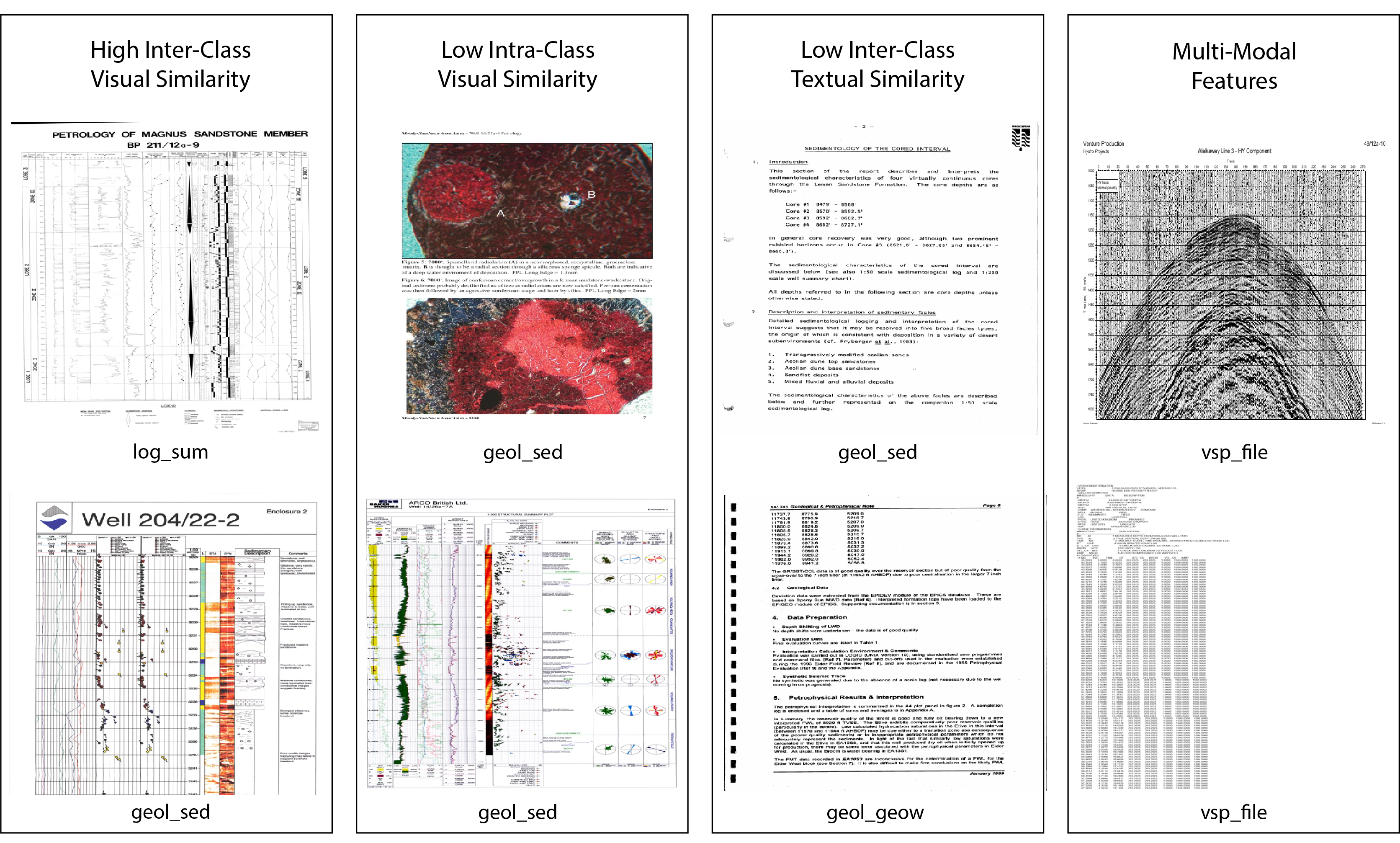
Figure 1: Sample NDR Page Images
Contemporary uni-modal document classification models used in the industry often rely on features from a single modality, either textual or visual. However, it is difficult to build a robust high performance uni-modal classifier over such a complex multi-modal dataset. For example, document classifiers making use of visual features extracted from page images may underperform due to the high inter-class similarity or intra-class variance of some document page images.
Document classifiers that rely on features from only the text modality tend to outperform image based classifiers at classifying oil and gas documents at a granular level. However these classifiers only perform well when enough text data is present in a document, some documents in the corpus such as diagrams and sample images do not contain any text making them impossible to classify using a text based approach alone. Other documents contain text that may be repeated across multiple document types. For example an oil well name and location being the only text data within visually different images such as between a map and a technical schematic, making them semantically similar but visually distinct.
This blog post explores using a multi-modal approach to oil and gas document classification, combining both text and visual modalities to create a more robust classifier for oil and gas exploration and production documents. With the hypothesis that a multi-modal classification approach combining text and visual feature input streams, will outperform a classifier trained on features from a single modality such as text or visual features.
Data Pre-processing
The document corpus for this project comes from the UK National Data Repository (NDR), an online repository maintained by the UK Oil and Gas Authority for the storage of petroleum related information and samples. The NDR contains hundreds of thousands of documents, representing 65 document types defined by labels known as CS8 Codes.
For the purposes of our experiment a document corpus was created by taking a random sample of approximately 1000 documents from each of 6 key document classes present in the NDR, with each document’s provided CS8 Code being used as a classification label. The document classes selected for inclusion in this dataset were; geological end of well reports (geol_geow), geological sedimentary reports (geol_sed), general geophysical reports (gphys_gen), well log summaries (log_sum), pre-site reports (pre_site) and vertical seismic profile files (vsp_file).
Feature Extraction
As this is a new dataset, the text and page image features needed to be extracted from each document in the NDR corpus, for use as training, validation and test data for evaluating each of the classification models. The raw documents were downloaded manually via the free to access NDR website where they are available under an open data license and processed using a feature extraction pipeline.
Unfortunately features were not successfully extracted from all documents, some older Microsoft Office documents could not be processed, while others were corrupt or had non-standard file formats. Several documents also did not contain any text content and therefore lack a text feature set.
| Document Class | Extracted Image Features | Extracted Text Features | Either Features |
|---|---|---|---|
| geol_geow | 1609 | 1477 | 1609 |
| geol_sed | 1013 | 964 | 1013 |
| gphys_gen | 1041 | 876 | 1041 |
| log_sum | 1051 | 887 | 1051 |
| pre_site | 1154 | 1053 | 1154 |
| vsp_file | 673 | 621 | 673 |
| Total: | 6541 | 5878 | 6541 |
Count of Feature Sets Extracted per Document.
Text Pre-Processing
The text feature dataset consists of a vector of integers T for each document representing the first 2,000 informative terms following text extraction and pre-processing. To create each vector, each document’s text first had to be extracted. Text extraction from ascii format files was achieved using native Python. For Microsoft Office files and PDF files with an embedded searchable text layer text was extracted using Apache Tika Server. For scanned PDF files without an embedded text layer and image format files, text was extracted using the Tesseract OCR Engine.
def start_tika_server(tika_path):
command = f'java -cp "{tika_path}" org.apache.tika.server.TikaServerCli ' \
'--port 80 --host 127.0.0.1'
tika_server = subprocess.Popen(
command, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL
)
try:
requests.get('http://127.0.0.1:80/tika')
except requests.exceptions.ConnectionError as e:
raise SystemExit(f'Unable to connect to Tika Server. {e}')
return tika_server
def extract_text(file):
tika_response = requests.put(
url=f'http://127.0.0.1:80/tika',
data=file,
headers={
'X-Tika-PDFOcrStrategy': 'no_ocr',
'X-Tika-OCRLanguage': 'eng',
'X-Tika-OCRTimeout': '1500',
'Accept': 'text/plain'
},
timeout=1500
)
tika_response = {
'content': tika_response.text,
'status': tika_response.status_code
}
return tika_response
The raw text extracted from each document was case folded to lower case and tokenized using the pre-trained Word Punkt tokenizer available in the NLTK library, into a sequence of individual tokens. Any tokens with low semantic value were then dropped from the sequence, including non-word tokens such as numbers and punctuation, as well as frequently occurring stopwords. Each token was then lemmatized to it’s base form using the Word Net lemmatizer in NLTK, this reduces dimensionality while preserving the semantic meaning of each token term.
def text_processing(text):
lemmatizer = nltk.stem.WordNetLemmatizer()
text = text.casefold()
text = text.translate(text.maketrans({'\'': None, '-': ' '}))
text = nltk.word_tokenize(text)
clean_tokens = []
for token in text:
if token in nltk.corpus.stopwords.words('english'):
continue
if not token.isalpha():
continue
if len(token) < 2:
continue
token = lemmatizer.lemmatize(token)
clean_tokens.append(token)
clean_string = ' '.join(clean_tokens)
return clean_string
The processed tokens were then converted to integers, this was achieved by creating a vocabulary set V containing all unique tokens extracted from each document and mapping each to a unique integer value v. The first 2,000 processed tokens for each document are then mapped to their corresponding v integer value in V to create a vector of integers T for each document. Any vectors with less than 2,000 integers are padded with 0 so that |T| = 2,000 giving a consistent input size for our models.
Image Pre-Processing
The visual feature dataset consists of sequences of JPEG images, with each sequence S containing image representations of the first ten pages of each document in the corpus. For documents in a non-image file format the pages were converted to image representations.
For PDF format documents each page was converted to a single JPEG image using the Poppler PDF rendering library.
from pdf2image import convert_from_bytes
with open(file_properties.file_path, 'rb') as pdf_file:
pdf_bytes = pdf_file.read()
page_images = convert_from_bytes(pdf_bytes, dpi=300, size=(500, 500))
For raw text format files a new blank image with all white pixels was created using a standard A4 page size of 1748 x 2480 pixels and the documents text content was fitted to and overlayed on each blank page image. For documents with less than ten pages, each sequence was then padded with blank 2D arrays with all pixel values in each array set to zero.
from PIL import Image, ImageDraw, ImageFont
font = ImageFont.truetype("arial.ttf", 16, encoding="unic")
def page_image(page_text, file_path):
image = Image.new('L', (1748, 2480), color=255)
draw = ImageDraw.Draw(image)
draw.text((20, 20), page_text, font=font)
image = image.resize((500, 500))
image = image.convert('RGB')
image.save(file_path, 'JPEG', quality=100)
Each extracted page image was then resized to 200 x 200 pixels using cubic interpolation to make them small enough to be fed into a classification convolutional neural network (CNN). This image size was selected as a compromise between the loss of information in the image verses the computational cost of a larger image size, as well as a desire for a consistent input size for the models. Larger input sizes may also lead to overfitting as the CNN may learn more granular features such as characters or image details that are only relevant to specific documents in the training dataset, instead of the overall general layout of documents within each class.
Certain documents within the corpus have pages with very large aspect ratios, documents in the comp_log class for example often have a vertical aspect ratio of c. 12.0 compared to the aspect ratio of 1.414 of a typical A4 document page. Resizing these images to 200 x 200 pixels causes significant loss of layout and image information. Therefore, page images with an aspect ratio greater than 2.0 were treated as though they covered multiple pages and split into multiple consecutive images, each with an aspect ratio of 1.414 prior to being resized, with each image being treated as a separate page in the document.
To further reduce unnecessary complexity the page images were converted to single channel greyscale format using Floyd-Steinberg dither to approximate the original image luminosity levels, the original RGB format images were also tested but when benchmarked with the uni-modal image classification model the accuracy gains were not significant and had a significant computational cost. As a final pre-processing step the pixel values in each page image were normalised by dividing each pixel value by the maximum pixel intensity value of 255.
Experiment Design
Experiment Goals
The experimental goal is to investigate the effectiveness of multi-modal deep learning at the task of classifying the multi-page documents within the NDR corpus.
First in order to provide a benchmark against which to measure the performance of the multi-modal models two uni-modal models will be evaluated, a text based classifier and a classifier built using page images.
Various multi-modal approaches that combine both document text and page images will then be explored using early, late and combined fusion architectures.
Model Hyperparameters
The majority of hyperparameters will be specific to each model architecture used in this work, however a number of hyperparameters are fixed for all models. This makes comparing the performance of the models easier and allows the combination of uni-modal model architectures into the more complex multi-modal models. Model specific parameters are adapted from previous work or determined experimentally and tuned using a grid search optimisation approach.
For the fixed hyperparameters the ReLU activation function is used for all hidden network layers, with a softmax activation function being used for all output layers. Every model also uses the Adam optimization algorithm to optimize a categorical cross entropy loss function, with the default TensorFlow learning rate of 0.001 providing a good balance of classification accuracy and performance when tested experimentally with various rates on both uni-modal models.
Model Training
The dataset used for training and evaluating each model will be split with 80% being used for training and 20% being used for testing model performance, with 10% of the training dataset being set aside for use in validation during model training. The dataset is split randomly and in a stratified manner to ensure an even split across all classes, a random seed is used to ensure reproducibility.
To avoid overfitting the models due to over-training the training process is terminated using an early stopping technique. At the end of each training epoch the model’s performance is measured against the validation set and if the validation loss has not decreased for two consecutive epochs, training is halted. The model weights are then reverted to the state with the lowest validation loss to produce the final trained model. Once training is complete each model will be evaluated using the same performance metrics; overall percentage accuracy, macro precision and recall scores, macro F1 score and the number of epochs each model takes to converge.
The stochastic nature of training a deep learning model also needs to be accounted for in the model evaluation process. A model with a set architecture can vary in performance due to a number of factors, including random weight and bias initialization values or the stochastic behaviour of the Adam optimisation algorithm as it traverses the error gradient. To compensate for the effect of model variance on the evaluation of model performance, each model is initialized and evaluated ten times with the average performance metrics of all ten initializations being taken as the models overall performance.
To measure how well the model generalises across the entire NDR dataset instead of simply optimising the model to predict a specific test sample, it is necessary to also vary the sub-samples used in training, validating and testing the model. Therefore a different random sample split is used for each iteration and to ensure the same sub-samples are used for each model a random seed is used in sequence to calculate each iterations split values.
Baseline Models
Text Classification Model
The text classification model used in this project is based on the simple 1D CNN model for text classification architecture. The original model had a simple architecture with just a single convolutional layer, followed by a global max pooling layer and a fully connected softmax output layer. To avoid overfitting or co-adaptation of hidden units, dropout is employed in the penultimate network layer, reportedly improving the performance by up to 4%. An l2 norm constraint is also applied to help further regularise the model.
The original model made use of pre-trained Word2Vec word embeddings trained on a 100 billion word Google News corpus using the continuous bag of words (CBOW) method as inputs. These dense embeddings attempt to capture the semantic and syntactic meaning of each word in the training corpus and have been shown to perform better than sparse representations such as TF-IDF or one hot encoding in text classification tasks.
Unfortunately generic pre-trained neural language models struggle to capture domain specific semantics and vocabulary, resulting in a large number of out of vocabulary terms. Therefore the generic Word2Vec model does not perform well for the classification of corpora with highly domain specific vocabularies, such as in the oil and gas industry specific NDR corpus. With this in mind the text classification model makes use of bespoke dense embeddings, learned during training through the use of a TensorFlow Keras embedding layer. The embedding layer is initialized with random weights, which are then updated during training to learn dense word embeddings, each with a vector length of 150 values. This approach has the advantage of learning embeddings specific to the classification task and corpus texts.
Despite having a relatively simple architecture, originally proposed for the classification of shorter sentences, this model has been shown to be very effective against well know document classification benchmark datasets. However hyperparameter tunning of the original model is required to maximise classification performance.
As a baseline the model was initially fitted and tested using the original architecture and hyperparameters as shown below. When trained with the original hyperparameters the model converged after an average of 23 epochs, the trained model had an average accuracy of 82.6%, average recall score of 0.83, average precision score of 0.83 and an average macro f1 score of 0.83 when evaluated against the test dataset.
| Hyperparameter | Original Model | Tunned Model |
|---|---|---|
| Kernel Size | 4 | 7 |
| Feature Maps | 100 | 200 |
| Activation Function | ReLU | ReLU |
| Pooling | Global 1-Max Pooling | Global 1-Max Pooling |
| Dropout Rate | 0.5 | 0.3 |
| l2 Regularisation | 3 | 0.5 |
| Dense Hidden Layers | 0 | 1 |
| Dense Layer Nodes | 0 | 50 |
Hyperparameters of Original (Zhang, 2017) and Tunned Model.
The model was then optimised for the task of classifying documents in the NDR corpus through hyperparameter tuning. A coarse grid search was performed on each of the following hyperparameters to find it’s optimal values relating to the models classification performance; the kernel size of each feature region and the number of feature maps in the convolutional layer, the dropout rate and the l2 norm constraint threshold.
def text_cnn_model(
doc_data, embedding_size=150, filter_maps=100, kernel_size=4,
dropout_rate=0.5, l2_regularization=3, dense_nodes=100, dense_layers=0,
optimizer='adam', loss='categorical_crossentropy'
):
input_layer = keras.layers.Input(shape=2000)
embeddings = keras.layers.Embedding(
doc_data.vocab_length,
embedding_size,
input_length=2000
)(input_layer)
conv_1d = keras.layers.Conv1D(
filters=filter_maps, kernel_size=kernel_size, activation='relu'
)(embeddings)
global_pooling = keras.layers.GlobalMaxPool1D()(conv_1d)
extracted_features = keras.layers.Flatten()(global_pooling)
if dense_layers > 0:
dense_layer = keras.layers.Dense(dense_nodes, activation='relu')(extracted_features)
for layer in range(dense_layers - 1):
dense_layer = keras.layers.Dense(dense_nodes, activation='relu')(dense_layer)
dropout_layer = keras.layers.Dropout(dropout_rate)(dense_layer)
else:
dropout_layer = keras.layers.Dropout(dropout_rate)(extracted_features)
regularise = keras.regularizers.l2(l2_regularization)
output = keras.layers.Dense(
6, activation='softmax', kernel_regularizer=regularise
)(dropout_layer)
model = keras.models.Model(inputs=[input_layer], outputs=[output])
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
return model
I also experimented with adding dense feed forward layers prior to the dropout and softmax output layers, finding that the addition of a single fully connected feed forward layer improved model performance while reducing the number of epochs taken for the model to converge. A coarse grid search was conducted using different numbers of nodes in the dense fully connected layer, finding 50 nodes to be optimal. Varying the number of convolutional layers in the model was also tested, as deeper architectures have been shown to be highly effective at text classification tasks. However in this case adding additional convolutional layers had a high computational cost and did not significantly improve model performance.
Once trained the tunned model yielded an average test accuracy of 86.3% for classifying documents containing text data, an improvement of 3.7% compared to the original model. The model also had an improved average macro F1 score of 0.86.
Page Image Classification Model
Two dimensional CNNs have revolutionised deep learning performance in the area of image classification, including the classification of document page images. Most prior work in document classification has focused on the use of CNNs to classify documents one page at a time as a continuous document stream of discrete page images. We attempt to replicate previous work in this area by first evaluating a single page CNN classifier on only the first page, then expanding this approach to multi-page document classification.
We then build on this work, evaluating a combined C-LSTM (Convolutional Long Short Term Memory) architecture that takes the original CNN network and places it within an LSTM network architecture to classify documents based on page image sequences. LSTM networks are a form of recurrent neural network capable of learning temporal relationships between the page images such as page order and proximity. This means they may perform better on the NDR document classification task, factoring the composition and order of multiple pages into a documents classification.
The single page CNN model architecture was adapted from previous work on page image classification, in which greyscale document page images similar to those in the NDR dataset were classified with an overall accuracy of 65.35%. The models architecture consists of two convolutional layers, and two max pooling layers, the output of which is fed into a two layer dense feed forward network with 1000 nodes in each layer, followed by a final softmax output layer. The first convolutional layer has 20 feature maps and kernel size of 7 x 7, the second convolutional layer has 50 feature maps and a kernel size of 5 x 5, both max pooling layers have 4 x 4 pooling kernels. The network is regulated by applying dropout at the penultimate layer at a rate of 0.5, this masks out the output activations from 50% of the neurons in the final dense layer. The model was tested with different dropout rates with the optimal dropout rate being 0.5 as per the original paper. The addition of zero padding on the output of the initial convolutional layer also improved model performance.
def image_cnn_model(
filter_map_1=20, kernel_size_1=7, filter_map_2=50, kernel_size_2=5,
pooling_kernel=4, dropout_rate=0.5, dense_nodes=1000, optimizer='adam',
loss='categorical_crossentropy'
):
image_input = keras.layers.Input(shape=(200, 200, 1))
conv_2d_1 = keras.layers.Conv2D(
filter_map_1, kernel_size_1, activation='relu', padding='same'
)(image_input)
pool_2d_1 = keras.layers.MaxPooling2D(pooling_kernel)(conv_2d_1)
conv_2d_2 = keras.layers.Conv2D(
filter_map_2, kernel_size_2, activation='relu', padding='valid'
)(pool_2d_1)
pool_2d_2 = keras.layers.MaxPooling2D(pooling_kernel)(conv_2d_2)
extracted_feature = keras.layers.Flatten()(pool_2d_2)
dense_1 = keras.layers.Dense(dense_nodes, activation='relu')(extracted_feature)
dense_2 = keras.layers.Dense(dense_nodes, activation='relu')(dense_1)
dropout_layer = keras.layers.Dropout(dropout_rate)(dense_2)
output = keras.layers.Dense(6, activation='softmax')(dropout_layer)
model = keras.models.Model(inputs=[image_input], outputs=[output])
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
return model
We then expanded the use of the single page CNN architecture to multi-page document classification. First an ensemble approach was tested with the majority vote being taken as a documents class, with the strength of the softmax probability prediction being used to resolve any conflicts. First the single page CNN model was trained on all ten pages from every document. The model was able to classify individual pages with an accuracy of 49% and F1 score of 0.48. During model evaluation, inference was performed on all pages in a document using the majority vote method to give a final prediction for the document as a whole. Unfortunately this approach performed poorly with an accuracy of 50%, which may be in part due to the model trying to classify zero padding images in the input sequence.
Following the poor performance of the majority vote approach the use of a simple neural network classifier was investigated to combine the output probabilities for each page into a single document classification. The theory behind trying this approach was that even a simple neural network should be able to learn to place less value on zero value padding images and similar pages across classes, while recognising meaningful class specific pages or probability combinations. The CNN output probabilities for each page were concatenated into a single feature vector and used as input to a simple three layer neural network classifier. The classifier architecture consisted of a 60 node input layer, a hidden 10 node fully connected layer and a 6 node softmax output layer, with the number of nodes in the hidden layer being determined by a grid search. When evaluated this approach gave a classification accuracy score of 72.4% a major improvement of 22.4% compared to the majority vote method and a significant accuracy improvement of 5.3% over the Single Page CNN.
The use of a C-LSTM model architecture was then investigated, with the aim of unifying multi-page classification into a single model that can learn important temporal relationships within document page sequences. The C-LSTM model uses the same CNN architecture as the single page model as time distributed feature extractors. The output sequence from the temporal CNN feature extraction layers is then fed into two uni-directional LSTM layers in place of the previous dense layers used in the Single Page CNN. The output of the final CNN layer is regulated using dropout prior to the final softmax output layer.
def image_cnn_lstm_model(
filter_map_1=20, kernel_size_1=7, filter_map_2=50, kernel_size_2=5,
pooling_kernel=4, dropout_rate=0.5, lstm_nodes=1000, optimizer='adam',
loss='categorical_crossentropy', bi_directional=False,
):
image_input = keras.layers.Input(shape=(10, 200, 200, 1))
conv_2d_1 = keras.layers.TimeDistributed(
keras.layers.Conv2D(
filter_map_1, kernel_size_1, activation='relu', padding='same'
)
)(image_input)
pool_2d_1 = keras.layers.TimeDistributed(
keras.layers.MaxPooling2D(pooling_kernel)
)(conv_2d_1)
conv_2d_2 = keras.layers.TimeDistributed(
keras.layers.Conv2D(
filter_map_2, kernel_size_2, activation='relu', padding='valid'
)
)(pool_2d_1)
pool_2d_2 = keras.layers.TimeDistributed(
keras.layers.MaxPooling2D(pooling_kernel)
)(conv_2d_2)
extracted_features = keras.layers.TimeDistributed(
keras.layers.Flatten()
)(pool_2d_2)
if bi_directional:
lstm_1 = keras.layers.Bidirectional(
keras.layers.LSTM(lstm_nodes, return_sequences=True)
)(extracted_features)
lstm_2 = keras.layers.Bidirectional(
keras.layers.LSTM(lstm_nodes, dropout=dropout_rate)
)(lstm_1)
else:
lstm_1 = keras.layers.LSTM(lstm_nodes, return_sequences=True)(extracted_features)
lstm_2 = keras.layers.LSTM(lstm_nodes, dropout=dropout_rate)(lstm_1)
output = keras.layers.Dense(6, activation='softmax')(lstm_2)
model = keras.models.Model(inputs=[image_input], outputs=[output])
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
return model
The C-LSTM model performed significantly better than the Single Page CNN, showing an improvement of 6.5% average accuracy. How ever it performed worse than the Multi-Page CNN with the additional neural network ensemble layer, which had a 1.1% higher accuracy. However this is only a marginal gain with the simpler single model architecture and faster inference making the C-LSTM a more practical choice. The use of bi-directional LSTM layers in place of the uni-directional LSTM layers was also evaluated but did not improve the average performance of the model. An overview of average performance metrics for each page image classification model has been provided in Table 4.
| Model Architecture | Average Accuracy | Average Precission | Average Recall | Average F1 | Average Epochs |
|---|---|---|---|---|---|
| Single Page CNN (First Page) | 67.1 | 0.69 | 0.68 | 0.68 | 4 |
| Multi-Page CNN (Majority Vote) | 44.8 | 0.59 | 0.42 | 0.4 | 3 |
| Multi-Page CNN (NN) | 72.4 | 0.75 | 0.73 | 0.73 | 3 + 7 |
| Uni-Directional C-LSTM | 71.3 | 0.74 | 0.72 | 0.72 | 8 |
| Bi-Directional C-LSTM | 70.3 | 0.73 | 0.71 | 0.71 | 8 |
Uni-Modal Page Image Classifier Performance.
Multi-Modal Models
Early Fusion Model
Early fusion in multi-modal deep learning involves the early concatenation of uni-modal features, usually immediately after feature extraction into a single joint representation. In deep neural network classifiers this single joint representation is then used as input to the models decision layers. The early combination of modalities prior to classification, allows the model to learn important inter-modal features and low level correlations across both modalities. This approach is loosely analogous to how biological neural networks perform multisensory convergence early on in their sensory processing pathways. However an early fusion model is less likely to learn strong modality specific features than models using late or hybrid fusion, which may hamper classification performance when one of the text or image modalities is missing.
The architecture of the early fusion neural network used for this experiment is a C-LSTM that concatenates the page image and text features post extraction to provide a joint representation. Feature extraction for each modality is initially performed separately, using an identical approach to feature extraction as that used in the previously evaluated uni-modal networks. A one-dimensional CNN, with word embeddings and a global max-pooling layer is used to extract features from the input text. A dual layer two-dimensional CNN is used to extract features from the input page images, consisting of alternating convolutional and max pooling layers. The extracted features from both are then flattened and concatenated into a joint feature representation, this is then fed into two LSTM cell layers followed by a single softmax layer that provides the classification prediction probabilities.
As in the uni-modal page image classification C-LSTM model a recurrent LSTM architecture is used to allow the model to learn important temporal relationships between the page images, however the LSTM cell layers require inputs to be a time distributed sequence. The image inputs already exist in an ordered sequence of ten pages and distributing them as inputs is trivial, however there is only a single instance of text input data per document. Therefore to create a joint feature representation that can be processed by the LSTM, the text data is replicated ten times to create a sequence of ten identical texts. This allows features from each page image to be concatenated with those from the documents extracted text and processed by the LSTM as a single temporally distributed joint sequence.
Due to the time and space complexity of the model as well as the large number of tuneable parameters, it was unfeasible to use grid-search or even Bayesian hyperparameter optimisation methods on all layers and parameters of the network. Therefore hyperparameter tunning was only carried out on the final LSTM and regularisation layers, making the assumption that the feature extraction layers have already been optimised for feature extraction on the input data during the tunning of the uni-modal models.
def early_fusion_model(vocab_length):
text_input = keras.layers.Input(shape=(10, 2000), name='text_input')
embeddings = keras.layers.TimeDistributed(
keras.layers.Embedding(vocab_length, 150, input_length=2000),
name='word_embeddings'
)(text_input)
conv_1d = keras.layers.TimeDistributed(
keras.layers.Conv1D(filters=200, kernel_size=7, activation='relu'),
name='1d_convolutional_layer'
)(embeddings)
global_pooling = keras.layers.TimeDistributed(
keras.layers.GlobalMaxPool1D(), name='max_pooling_layer'
)(conv_1d)
image_features = keras.layers.TimeDistributed(
keras.layers.Flatten(), name='text_features'
)(global_pooling)
image_input = keras.layers.Input(shape=(10, 200, 200, 1), name='image_input')
conv_2d_1 = keras.layers.TimeDistributed(
keras.layers.Conv2D(20, 7, activation='relu', padding='same'),
name='2d_convolutional_layer_1'
)(image_input)
pool_2d_1 = keras.layers.TimeDistributed(
keras.layers.MaxPooling2D(4), name='2d_max_pooling_layer_1'
)(conv_2d_1)
conv_2d_2 = keras.layers.TimeDistributed(
keras.layers.Conv2D(50, 5, activation='relu', padding='valid'),
name='2d_convolutional_layer_2'
)(pool_2d_1)
pool_2d_2 = keras.layers.TimeDistributed(
keras.layers.MaxPooling2D(4), name='2d_max_pooling_layer_2'
)(conv_2d_2)
text_features = keras.layers.TimeDistributed(
keras.layers.Flatten(), name='image_features'
)(pool_2d_2)
joint_features = keras.layers.concatenate([text_features, image_features])
lstm_1 = keras.layers.LSTM(450, return_sequences=True)(joint_features)
lstm_2 = keras.layers.LSTM(1000)(lstm_1)
dropout = keras.layers.Dropout(0.5)(lstm_2)
output = keras.layers.Dense(6, activation='softmax')(dropout)
model = keras.models.Model(inputs=[text_input, image_input], outputs=[output])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
A coarse grid search was performed on a per feature basis, exploring the number of nodes in each LSTM layer and the dropout rate applied to regulate the model at the penultimate layer. This process identified 1000 nodes and a dropout rate of 0.5 was optimal for the final LSTM layer, interestingly creating a bottleneck by using only 450 nodes in the first LSTM layer led to a reasonable increase in classification performance.
The addition of a dense fully connected layer between the final LSTM and softmax output layer was also tested with varying numbers of nodes, however this layers addition was found to degrade the models performance. The final high level architecture for the early fusion model is shown in Figure 2.
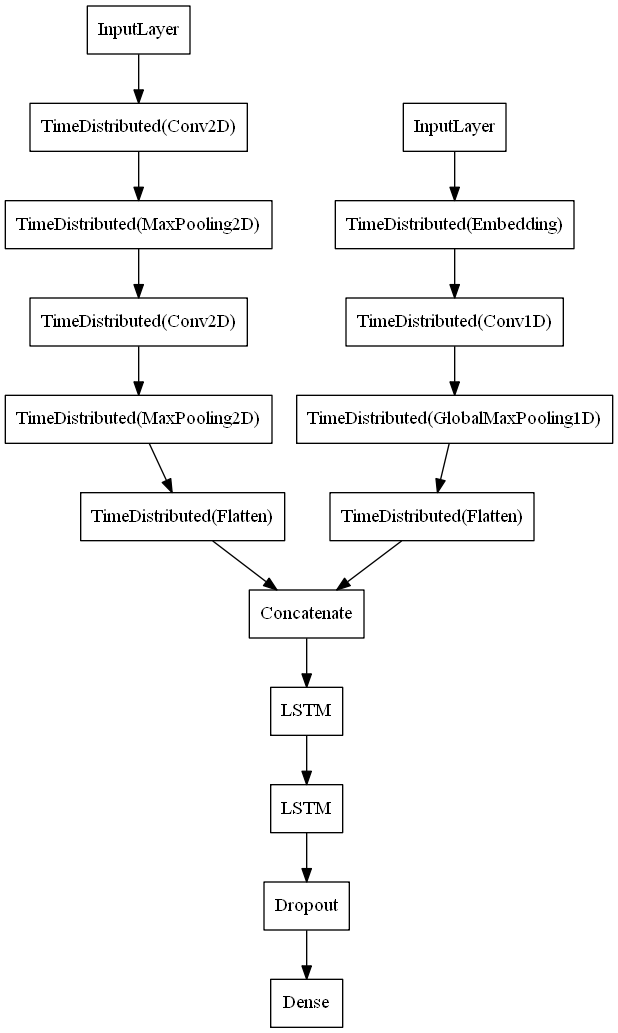
Figure 2: Early Fusion Model Architecture
Late Fusion Model
The late fusion method makes use of two separate uni-modal networks and fuses their semantic output representations at decision time. Each uni-modal network performs feature extraction and learns strong modality specific representations for use in document classification, the output of the final layer of each uni-modal network is then fused to give a join classification decision. This approach in theory allows the model to be more robust to missing data from one modality.
There are a number of approaches to late fusion in deep neural classifier networks, in some approaches the uni-modal networks are trained separately, then their free parameters are frozen and the output of their penultimate layers fused together by a dense fully connected output layer. The approach taken for our late fusion model is similar, however the weights and biases in the uni-modal models are not frozen and trained together as part of a multi-modal network.
def late_fusion_model(vocab_length):
# Text CNN
text_input = keras.layers.Input(shape=2000)
embeddings = keras.layers.Embedding(vocab_length, 150, input_length=2000)(text_input)
conv_1d = keras.layers.Conv1D(filters=200, kernel_size=7, activation='relu')(embeddings)
global_pooling = keras.layers.GlobalMaxPool1D()(conv_1d)
flatten = keras.layers.Flatten()(global_pooling)
dense_layer = keras.layers.Dense(
50, activation='relu', kernel_regularizer=keras.regularizers.l2(0.5)
)(flatten)
text_features = keras.layers.Dropout(0.3)(dense_layer)
# Image CNN LSTM
image_input = keras.layers.Input(shape=(10, 200, 200, 1))
conv_2d_1 = keras.layers.TimeDistributed(
keras.layers.Conv2D(20, 7, activation='relu', padding='same')
)(image_input)
pool_2d_1 = keras.layers.TimeDistributed(keras.layers.MaxPooling2D(4))(conv_2d_1)
conv_2d_2 = keras.layers.TimeDistributed(
keras.layers.Conv2D(50, 5, activation='relu', padding='valid')
)(pool_2d_1)
pool_2d_2 = keras.layers.TimeDistributed(keras.layers.MaxPooling2D(4))(conv_2d_2)
extracted_features = keras.layers.TimeDistributed(keras.layers.Flatten())(pool_2d_2)
lstm_1 = keras.layers.LSTM(1000, return_sequences=True)(extracted_features)
image_features = keras.layers.LSTM(1000, dropout=0.5)(lstm_1)
# Fused Feed Forward Softmax Classifier
concat_features = keras.layers.concatenate([text_features, image_features])
output = keras.layers.Dense(6, activation='softmax')(concat_features)
model = keras.models.Model(inputs=[text_input, image_input], outputs=[output])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
The late fusion model was constructed by taking the architectures of the uni-modal 1D text classification CNN and uni-directional C-LSTM page image sequence classification models and replacing their output layers with a single shared six node softmax output layer. Each uni-modal network is otherwise left unchanged, with the same layers, regularisation and other hyperparameters as the original models. The final high level architecture for the late fusion model is shown in Figure 3.
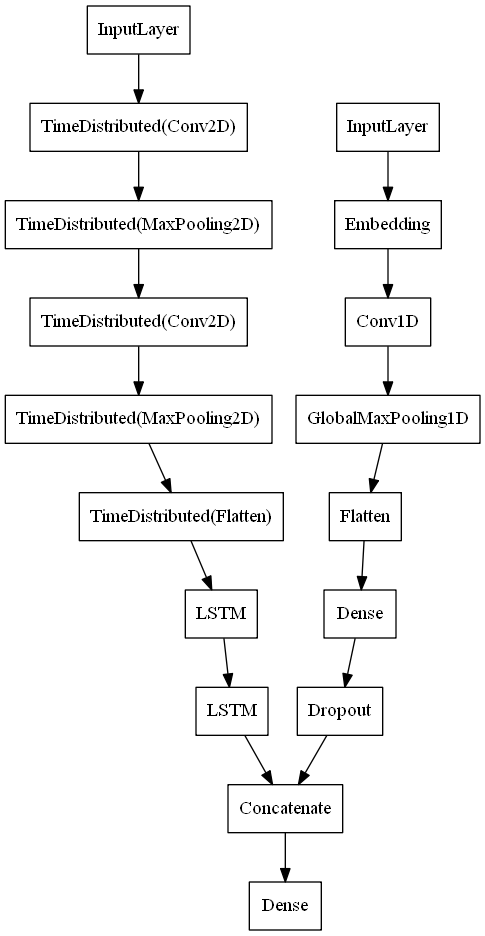
Figure 3: Late Fusion Model Architecture
Hybrid Fusion Model
Hybrid fusion networks attempt to combine the benefits of the early and late fusion strategies, with the goal of creating a model that can learn both strong feature and decision level strategies. The hybrid model used in this experiment combines the architectures of the previous early and late fusion models, concatenating the penultimate layers into a single representation connected to a softmax output layer. The final high level architecture for the hybrid fusion model is shown in Figure 4.
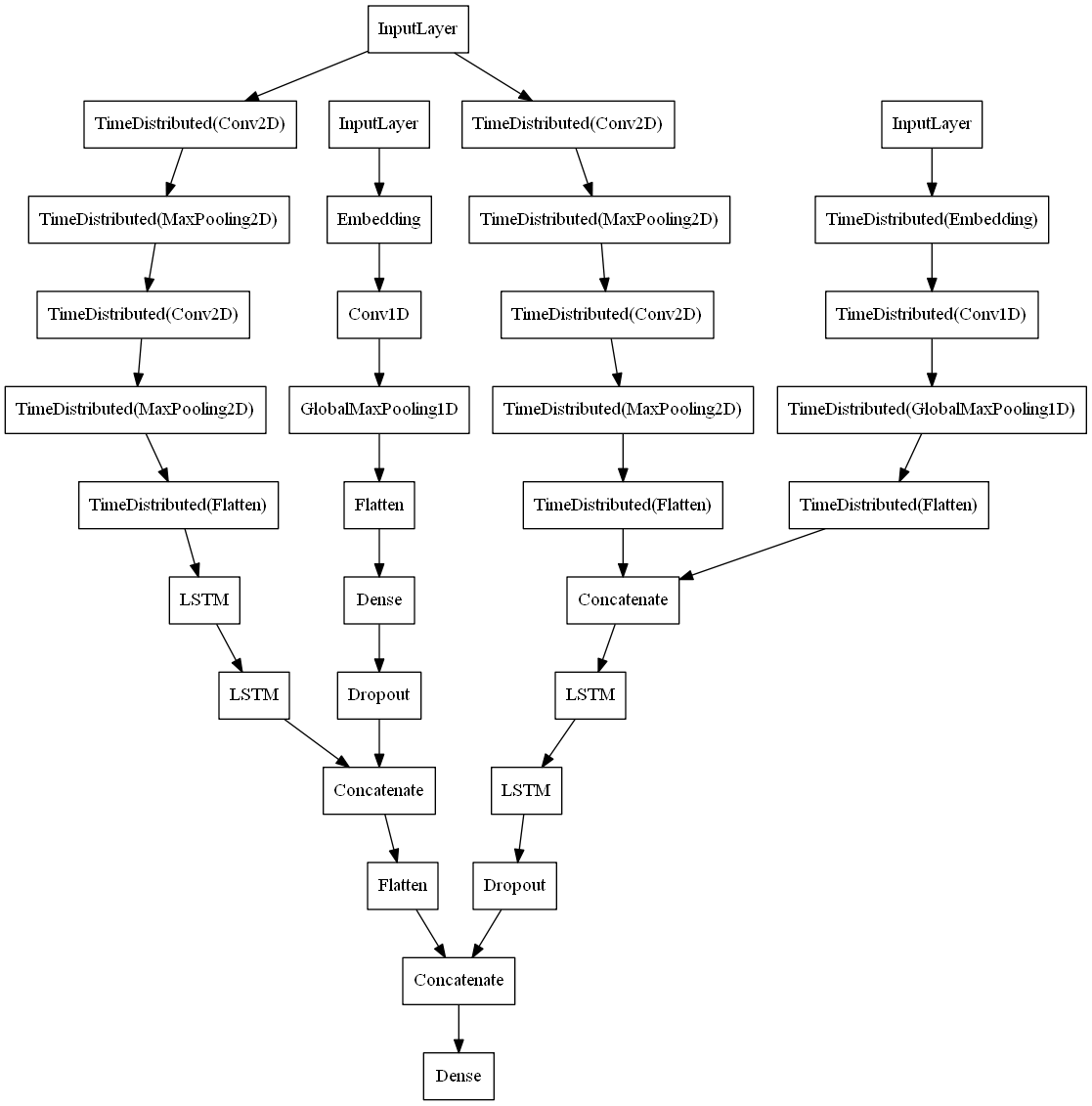
Figure 4: Hybrid Fusion Model Architecture
Evaluation
Model Benchmarking
To assess the average classification performance of the different fusion strategies, each of the fused models were trained and benchmarked against two datasets from the NDR corpus. To measure general performance and allow for benchmarking against the uni-modal text classification model, each multi-modal model was benchmarked against a sub-set of the NDR in which all documents contained both page image and text features, this will from now on be referred to as the Dual Modality Dataset.
Then to measure the robustness of the models in classifying documents that lack any text data, each model was also trained and benchmarked against the entire NDR corpus, we will refer to this as the Complete Dataset. This allows any loss in classifier performance due to a uni-modal image only input to be quantified, as well as allowing the multi-modal models to be benchmarked against the uni-modal image classification CNN model. It’s worth noting that robustness to this type of input is is an important performance benchmark as documents that lack text data are common in the NDR corpus and the wider Oil and Gas industry, examples of these document types include microscopy images, seismic profiles and some maps.
To measure if the performance difference between similarly performing models is statistically significant the Wilcoxon signed-rank test is used to calculate a p-value. This test has been selected as it is more robust to the non-independence of performance values caused by the random resampling approach used to evaluate each model multiple times across the dataset and does not assume homogeneity of variance. This allows us to test the null hypothesis that the difference in performance between to models may be due to random chance, we can reject this hypothesis if the score is below the widely used threshold of 0.05.
Outcomes and Analysis
The multi-modal models were benchmarked against the Dual Modality and Complete datasets and the average classification performance metrics obtained are below.
For the dual modality dataset:
| Model Architecture | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Text 1D-CNN | 86.3 | 0.86 | 0.86 | 0.86 |
| Early Fusion C-LSTM | 82.5 | 0.84 | 0.83 | 0.83 |
| Late Fusion C-LSTM | 84.2 | 0.85 | 0.85 | 0.85 |
| Hybrid Fusion C-LSTM | 82.3 | 0.84 | 0.83 | 0.83 |
For the complete dataset:
| Model Architecture | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Multi-Page CNN (NN) | 72.5 | 0.75 | 0.73 | 0.73 |
| Early Fusion C-LSTM | 77.3 | 0.8 | 0.78 | 0.78 |
| Late Fusion C-LSTM | 81.1 | 0.82 | 0.81 | 0.81 |
| Hybrid Fusion C-LSTM | 77.2 | 0.81 | 0.77 | 0.78 |
For the Dual Modality Dataset the tuned uni-modal one dimensional CNN text classification model was the strongest performing classifier, this model significantly out performed the multi-modal classifiers when text data was available with an average accuracy 2.1% higher than the best performing multi-modal classifier. This suggests that the semantic and syntactic features extracted from a document’s text content are, when available, perhaps much stronger indicators of a documents classification than visual features such as page layout or image content. This is possibly also in part due to the high inter-class visual similarity of some document page images, such as title pages, all text pages or the identical all zero value padding images added to pad shorter page image sequences during pre-processing.
Out of the multi-modal fusion strategies, the Late Fusion C-LSTM had the highest average accuracy of 84.2%, however this is only 1.7% greater than the average accuracy of the Early Fusion C-LSTM model and not statistically significant with a high p-value of 0.09. This means we must accept the null hypothesis and accept that any performance difference between the two models is likely due to random chance, possibly related to the stochastic nature of initializing and training deep neural networks. The Late Fusion C-LSTM also outperforms the Hybrid Fusion C-LSTM network by a small average accuracy percentage of 1.7%, however a p-value of 0.028 means the null hypothesis is rejected suggesting that the Hybrid Fusion C-LSTM may be marginally less performant.
On the Complete Dataset all of the multi-modal models significantly out- performed the uni-modal CNN (NN) model which had an average accuracy of 72.4% which is 5.8% lower than the most poorly performing and 9.7% lower than the best performing multi-modal models. The performance of the Early and Hybrid Fusion C-LSTM models is nearly identical with an average accuracy difference of 0.1% and a high p-value of 0.86, leading us to accept the null hypothesis that these models are equally performant on this dataset. The Late Fusion C-LSTM model had the highest performance accuracy of 81.1% which is an average performance increase of 3.85%, which when combined with p-value scores of 0.004 when compared with the other multi-modal classifiers allows us to reject the null hypothesis.
The low p-value and robust average accuracy strongly suggest that the Late Fusion CLSTM architecture is the most performant architecture for document classification prediction over the entire NDR Dataset and the most robust to a lack of text modality input. It is interesting to note that there is an increase of 0.6 in the standard deviation of the average accuracy of the Late Fusion CLSTM model when benchmarked against the Complete Dataset, suggesting that the rate of text data sparsity may have some impact on the models performance across the dataset as a whole.
Final Thoughts
The best performing architecture was the Late Fusion C-LSTM model architecture which performed well when benchmarked against both traditional uni-modal text and image classifiers. It was also robust to single modality input, significantly outperforming our uni-modal page image classifier. It is hoped that this work provides some useful learnings that can be put towards tackling the problem of retrieving useful data currently locked away in the large unstructured document repositories that typically exist within most major Oil and Gas companies.
With only access to the single Nvidia GeForce RTX 2070 GPU in my home desktop PC, the compute power available to this project was limited and restricted the number of experiments that could be carried out. This project also only explored the multi-modal classification of documents from only 6 of the 65 document classes available in the NDR. I suspect that with an increased compute capacity and additional data will yield much improved multi-modal architectures.