
Neo4j Super Node Performance Issues
Published:
We recently developed a multi-billion relationship scale knowledge graph, representing the wider academic landscape. How we developed the data pipeline to build this graph in Neo4j is a story in itself, one I may write up here or on the Wellcome Data blog. This post however focuses on a specific database modelling issue that has caused us severe query performance issues, the issue of low cardinality “super nodes”.
What are Super Nodes?
Nodes with a large number of relationships (there is no formal number, but roughly 100k or more relationships) are known as “super nodes”. These high degree nodes may occur either due to the underlying structure of the real world network the graph represents, or the presence of low cardinality node types (nodes with a small number of possible categorical values) in the data model. The possible underlying causes of super nodes are well explained by David Allen in his blog post here.
For us it was a case of our data outgrowing our original data model, with performance issues surfacing only once we had fully populated our knowledge graph. These issues presented as very slow queries when traversing or filtering relationships on certain node types, sometimes taking several days for relatively simple queries to run. On investigation I noticed these node types contained many nodes that were acting as super nodes in our graph.
Super nodes can impact performance in a number of ways:
The default token lookup index Neo4j creates for each relationship only contains relationship type information. This means Neo4j has to assess all connections from a node it is traversing in a query, so it can identify the next node in the traversal.
Dense nodes can also increase the number of relationships within a given relationship type, which may make queries slower.
When creating a new relationship between nodes in the database, it is common practices to use MERGE to check such a relationship does not already exist. Neo4j will check if the relationship yet exists, which will be slower where there are a large number of relationships.
Super nodes can also lead to issues with scalability, as everything in the network is close to everything else, making the data hard to break into partitions.
Field of Research Example
As an example our data model included Field of Research (FoR) nodes, which each represent a broad category of scientific research as defined by ANZSRC. There are 100 million Publication nodes in our database, each linked to one or more of the 176 Field of Research nodes.
A Field of Research super node, with a sample of it's connected nodes displayed.
In a best case scenario, where the number of relationships is evenly distributed, each field of research would be linked to approximately 568,000 publications. However in reality publications from a small number of fields of research are over represented in our database, meaning millions of publications may have a relationship with a single field of research.
For example the below Cypher query returns all researchers who have published clinical science papers in 2020:
MATCH
(r:Researcher)-[a:AUTHORED]->(p:Publication {year:2020})
-[]-(f:FieldOfResearch {name:"Clinical Sciences"})
RETURN r
This query would take an extremely long time to execute as several million unindexed relationships between publications and the clinical science FoR node need to be checked during query execution.
Improving Perfomance
Query Refactoring
The simplest way we can improve performance is to refactor our queries to make them more efficient. One of the simplest ways to do this is to ensure both the relationship type and directionality are defined in the Cypher query.
//Non-directional and undefined
MATCH(p:Publication)-[]-(p:FieldOfResearch)
//Directional and defined
MATCH(p:Publication)-[l:LINKED]->(p:FieldOfResearch)
Unfortunately this does not help in our use case as all of the super nodes in our model have mono-directional, single type relationships with their related nodes.
Indexing Relationships
Neo4j does index relationships by default using a token lookup index that only contains type information for each index rather than information on which nodes they connect. However since version 4.3, Neo4j also supports indexing on relationship properties, this can be used to reduce the number of relationships that have to be checked during query execution.
For example the relationship between a Field of Research and a Publication node might have a publication_year property, which could be used as a filter to reduce the number of relationships required in a query by filtering to a specific year:
MATCH(p:Publication)-[l:LINKED {year:2020}]->(p:FieldOfResearch)
This moderately improves performance of some queries where the use of this property is an appropriate filter. However in our data model there are no properties that could reasonably be used as filters, and these relationships are often queried in bulk reducing any performance advantage.
Refactoring Super Nodes to Node Properties
Another option, that swaps our unreasonable execution time for a more reasonable increase in spatial complexity, is to refactor the super nodes in our data model to properties on their related nodes. This is especially appealing given the super nodes in our model are categorical, with single type, unidirectional relationships.
For example a relationship between a publication and a field of research super node, could be set instead as a property on the Publication node. These properties could then be indexed to further improve query performance, and the redundant super nodes and their many relationships could then (carefully) be removed from the graph.
Refactoring super nodes to properties did improve the performance of our queries, particularly those that include, but do not filter on the new super node property. There was a wrinkle though, the incoming relationships on the super nodes were one to many relationships, meaning the new super node properties have multiple values.
For example a publication node could be linked to multiple field of research nodes:
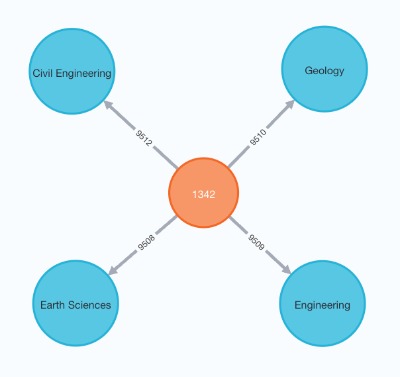
A Publication node linked to multiple Field of Research super nodes.
The properties of these field of research nodes now need to be set as properties on the publication node. Initially we used a list property to store these values, with a single list property for each of these values. This however is still not optimal as Neo4j does not currently support indexing on the elements within lists, making these slow to query at scale.
Full Text Indexes to The Rescue
Neo4j does however support full text indexes for string properties and make them fully searchable using the Apache Lucene search and indexing library. Neo4j also allows the specification of the analyzer Lucene should use to tokenise the text for index and querying. One of the available analyzers is “whitespace” which breaks text into individual searchable word tokens based on the Java whitespace standard.
By converting our list elements to a single string type property, we were able to leverage the full text index to drastically improve query times when filtering by any of the list elements. To convert the lists to a string, we first replaced the white space in each element with an _ then merged the elements into a single long space separated lower case string.
For example the field of research list property:
field_of_research:[
"Civil Engineering",
"Geology",
"Earth Sciences",
"Engineering"
]
Was converted to the string property:
field_of_research:"civil_engineering geology earth_sciences engineering"
These new string properties were then indexed with the full text index configured to use the whitespace analyzer, using the below Cypher procedure:
CREATE FULLTEXT INDEX field_of_research_fultext
FOR (p:Publication)
ON EACH [p.field_of_research]
OPTIONS {
indexConfig: {
`fulltext.analyzer`: 'whitespace'
}
}
Making it possible to use full text search to efficiently filter by the element in each string property.
CALL db.index.fulltext.queryNodes(
"field_of_research_fultext",
"earth_sciences"
)
YIELD node
MATCH (node)<-[]-(r:Researcher)
RETURN node, r
Performance Improvement
Migrating field of research from it’s own Field of Research node type to a full-text indexed property on each publication node has drastically improved query times. With queries seeking to find all publication nodes in a given year, linked to specific fields of research have gone from taking nearly a day to execute to a few seconds.